Last updated at Mon, 06 Nov 2017 20:34:02 GMT
Overview

As stated on their official homepage, Redis is an open source (BSD licensed), in-memory data structure store, used as database, cache and message broker.
Little bit about what Redis can do. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperlog and geospatial indexes with radius queries. Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster, meaning with Redis you can have support for distinctly different needs.
One of the core use cases for Redis is to facilitate horizontal scaling of your application. While trying to accomplish such a task, various issues are bound to arise. Sharing common data between components, and access to that data is just one among them. Let’s explain this a little better with an example.
The problem
Imagine a case in which you have a data structure like a list, map or a queue. This data structure needs to be accessed by all 6 instances of your distributed application, each of which is running on a different node. To the outside world however, your application behaves as if it is running on a single node. It appears this way because the application is hidden behind some load balancing system which is making sure the workload gets applied equally. However, in reality there are 6 applications running in isolation, sharing only local network services. This leads us to a question:
How can we assure that the nodes are sharing the same data space for common data, which needs to be accessed like any ordinary structure residing in RAM?
In the next part of this blog entry, we will we will focus on satisfying a Consumer-Producer problem which demonstrates our problem from above, and also how using Redis as a Task Queue can solve this.
Queues and Tasks
The problem scenario is that we have a Queue data structure, and a producer module of our application will be adding some tasks to the queue for execution at a later point. On the other side, a consumer module will be taking tasks off the queue and executing them when it is able to, e.g. when free bandwidth becomes available.
The consumer module can autonomously decide when to consume the tasks that are currently in the queue. For the sake of simplicity, let us assume, since we have 6 instances of our application running, there will be 6 producer modules sending data to a queue, and 6 consumer modules contending for that data in our queue.
One thing that’s very important here is transactional isolation. This means that 2 isolated consumer modules cannot take the same task off the queue. One feature of Redis is that a task cannot leave the control of Redis until it has completed. So in this case, Redis transfers the task into another Queue, let’s call it the ‘work’ or ‘processing’ queue. Each task will be deferred to this work queue before being given to the application. In the event of a consumer module freezing or crashing during work on a task, Redis will be aware of a ‘hanging’ task that has resided for a longer time in ‘work’ Queue, meaning that the task will not get lost inside a frozen application, but rather returned back to a wait queue to be consumed again by another consumer instance.
Flow of execution
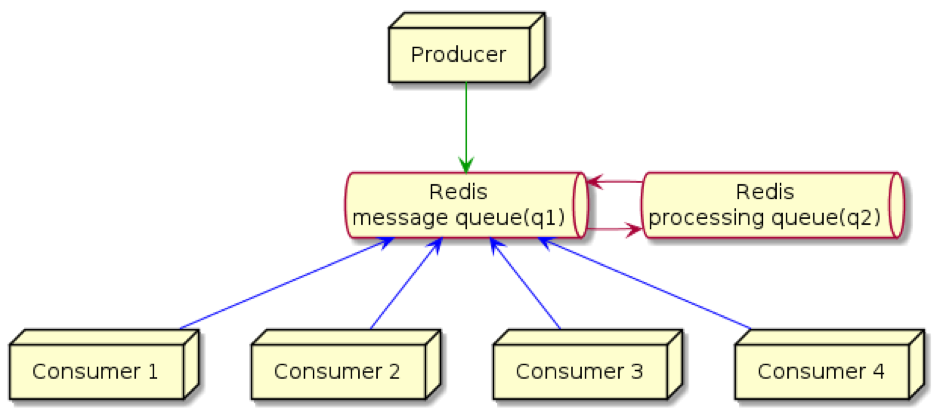
So in this instance, we have 2 queues, q1 and q2. The producer puts tasks on q1, the consumer then automatically pops an element off of q1 and puts it onto q2. After it’s been processed by the consumer, the message is deleted from q2. The second queue (q2) is used to recover from failures (network problems or consumer crashes). If messages are equipped with a timestamp, then their age can be measured, and if they sit in q2 for too much time, they can be transferred back to q1 to be re-processed again (by a consumer).
Implementation
Let’s take a look at a sample implementation of the Consumer and Producer problem we discussed above. There are communication modules that exchange information with a Redis server, written in Java. In this example, we will use the Jedis library. As the author states:
Jedis is a blazingly small and sane Redis java client.
Jedis was conceived to be EASY to use.
Jedis is fully compatible with Redis 2.8.x and 3.0.x.
First, we’ll construct a build channel Adapter class, as a point of communication between the application instance and Redis service. The class will expose methods whose functionalities are:
- send task to wait queue,
- check for available tasks in wait queue
- return task to wait queue from work queue
- remove task from work Queue
- get list of tasks in work Queue
Let us approach building a java Class that will be in charge of supporting those functionalities. The class will be built modularly in a sense that all needed dependencies should be injected during instantiation time, so we can easily set up test scenarios in which class would have injected mocked dependencies instead of real ones and tested against functional requirements.
So, as you can see from the code snippet above, our Adapter class has a single outer dependency (jedis pool instance) and two channels with which it will communicate. (These are hard-coded for simplicity sake).
When a producer module has a task that it is ready to work with, it will be delegated to the wait queue. Here we will use Redis’ LPUSH (left push) command. This method converts the entry parameter, Task (Job) object into a String-based structure, in our case we used Json as a means of representation of our object while residing inside Redis. The process of getting an available Jedis instance from the Jedis Pool and then pushing the message to our Queue is wrapped inside a try-catch block. We do this in case anything goes wrong with the process. The problem will be logged and the taken resource will be freed. For clarity here, we did not take into consideration what will happen if the process of getting a free Jedis instance results in getting null, or if a call to an instance.close() results in Exception thrown.
Log from Redis
You can log from Redis with a free Logentries account and the Logentries Diamond handler.
The central method used by the Consumer module is one that polls if there is something waiting in the wait Queue to be processed, so let’s take a look at it:
The central point of this method is instance.rpoplpush(). This is the call that transfers into Redis’ LPOPRPUSH call which tries to pick an element from Wait queue and transfer it into Work Queue, all done in a single transaction so there is no way a message can get lost in the middle of the process, it will either be left in Wait Queue (should there emerge any kind of problem) or the successful transaction will end up having our Job object transferred into Work Queue and returned to a Consumer Application module.
Let’s check on one more interesting implementation, getting a list of currently active processes.
Here we are using a Redis method call LRANGE which will return N elements of the desired channel. We need to pass in a starting element followed by the number of elements. Start element is obviously 0 (first element of the list), while ending element is set to -1. We set it to -1 so that Redis knows that we want all elements in a Queue. The rest of the method is instantiating an ArrayList object with its initial space set to a size of the list from the Redis driver and a for-loop that populates our list with converted messages into Batch objects.
The source file can be found here:
https://gist.github.com/asabo-rapid7/b71bf9ef4d51ccd024465e42ed1aa8fa
Conclusion
With Redis we can easily accomplish data interchange among our application instances so that all instances share the same memory space, thus appearing as being a single instance, accessing data in a transactionally isolated manner, with all the benefits of failover, persistence, and scaling being at hand ready should there be a need to.
